پردازش زبان طبیعی NLP

NATURAL LANGUAGE Processing پردازش زبان طبیعی
پردازش زبان طبیعی یا NLP شاخهای از دانش هوش مصنوعی است که برای درک زبان انسانی توسط رایانه به کار گرفته شده است. به دلیل پیچیدگی زبان انسانی، تا کنون زبانشناسان، کارشناسان علوم رایانه و دانشمندان هوش مصنوعی متعددی در پیشرفت این علم دخیل بودهاند.
تاریخچه پردازش زبان طبیعی
در سال ۱۹۵۰، آلن تورینگ با انتشار مقاله آزمایش تورینگ آغازگر دانش پردازش زبان طبیعی شد. آزمون تورینگ به عنوان ملاکی برای سنجش میزان هوشمندی ماشین مورد استفاده قرار میگرفته است. پس از آن، در سال ۱۹۵۷نوام چامسکی، زبانشناس سرشناس آمریکایی، با انتشار کتاب ساختارهای نحوی کمک شایانی به پیشرفت دانش NLP کرده است.
مراحل پردازش زبان طبیعی
پردازش زبان طبیعی دارای یک روند چند مرحله میباشد. برای مثال، هنگامی که شما با یک دستیار صوتی صحبت میکنید این مراحل عبارتند از:
- صحبت انسان با دستگاه دیجیتال
- ضبط صدای انسان توسط دستگاه صوتی
- تبدیل صدای انسان به متن
- پردازش متن و تولید پاسخ متنی مناسب
- تبدیل پاسخ متنی به صوت
- پخش فایل صوتی توسط دستگاه
برخی از کاربردهای رایج پردازش زبان طبیعی
ترجمهی ماشینی و ویرایشگرهای متن
هنگامی که از گوگل ترنسلیت استفاده میکنید و یا برای ویرایش متن خود از ابزارهایی مانند Grammerly و مایکروسافت ورد استفاده میکنید، در حقیقت شما در حال استفاده از توانایی سیستمهای کامپیوتری در پردازش زبان طبیعی میباشید.
تحلیل عواطف و سیستمهای توصیهگر
NLPرایانهها را قادر میسازد تا احساسات درون متنی را همچون دیدگاه مثبت یا منفی، دیدگاه منتقدانه و دیدگاه تأییدگر، درک کنند و در صورت لزوم برای ارائه خدمات بهتر پیشنهاداتی ارائه دهد.
دستهبندی متون و یادگیری ماشین
یادگیری زبان طبیعی به کمک دانش یادگیری ماشین به منظور دستهبندی متنها در گروههای مختلف تاریخی، ادبی و… مورد استفاده قرار میگیرند.
دستیارهای صوتی و گفتگوهای تعاملی
دستیارهای صوتی مانند سیری و الکسا یا chatbotهای فروشگاههای آنلاین، هر کدام در سطح متفاوتی از پردازش زبان طبیعی برای درک اطلاعات ورودی و تولید پاسخ مناسب استفاده میکنند.
چرا NLP از اهمیت بسیاری برخوردار است؟
در دنیای کنونی و با وجود جستجوگرهایی همچون گوگل، مصرفکنندگان نیازهای خود را با سرچ کردن یک نام، عبارت و یا حتی یکایده جست و جو خواهند کرد و در کسری از ثانیه با گزینههایی رو به رو میشوند که بصورت اختصاصی پیشنهاد شده و تا حد امکان مطابق هدف فرد از جست و جو میباشد.
این نحوه از پاسخگویی نیازمند پردازش اطلاعات با حجم بسیار بزرگ و سرعت بالا میباشد که از عهده انسان بر نخواهد آمد.
NLP یک ابزار قدرتمند مرتبط با یادگیری ماشین است که منجر به تقویت تیمهای انسانی میشود و به شرکتها کمک میکند تا بتوانند در بازار رقابتی پیشرو باشند. در حقیقت یک رایانه هوشمند میتواند با درک نیاز و پاسخ نیاز مصرفکننده یک تجربه به یادماندنی و لذت بخش برای مصرفکننده ایجاد کند.
نیاز: تقاضای مشتری، شامل هم معنیهای کلمات مورد استفاده
پاسخ نیاز: محصول و تمام الفاظی که تولیدکنندگان برای آن محصول بکار میبرند.
حقیقت اول: جستجو ضعیف سایت = از دست دادن مشتری مشتریان نیازهای خود را به روشهای نامحدودی جست و جو میکنند؛ در طرف دیگر فروشندگان محصولات خود را با فهرست محدودی از مجموعه واژگان توصیف میکنند. در نتیجه همواره شکافی میان عبارتی که مشتریان جست و جو میکنند و عباراتی که فروشندگان محصولات خود را با آن توصیف میکنند وجود دارد که بر کیفیت تجربه خرید مشتریان تأثیرگذار است. طبق اعلام CIO، ضعف سایت در جست و جو و هدایت بازدیدکنندگان جزء ۱۲ دلیل شایع شکست خوردن سایتهای فروش آنلاین میباشد.
جست و جوی ناکارآمد منجر به تلف شدن زمان ارزشمند افراد میشود. ۱۰ ثانیه ابتدایی مشاهده یک صفحه اینترنت نقش تأثیرگذاری در ماندن و یا ترک کردن یک سایت توسط بازدیدکننده خواهد داشت.
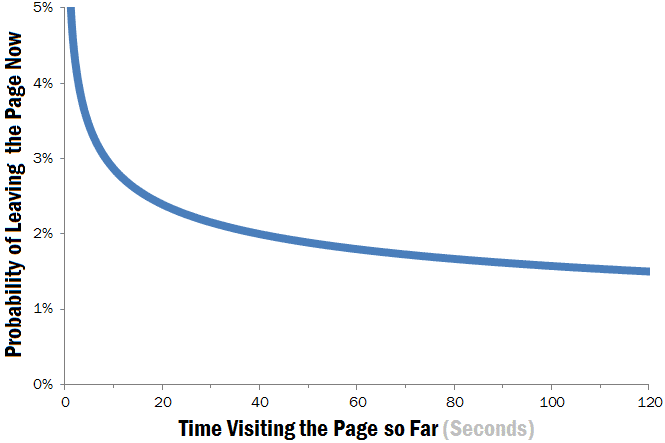
به زبان ساده، نتیجه جست و جو باید معنا دار باشد، و لازم است سریع و آسان باشد در غیر این صورت بازدیدکنندگان سردرگم میشوند که به معنی از دست دادن مشتری میباشد.
حقیقت دوم: انسان به تنهایی قادر نیست حجم دادههای موجود را کاوش کند.
کمپانیها مرتباً از نیاز، قصد، ترجیح و علاقهمندی مشتریان خود میآموزند. این پدیده دادههای بدست آمده از بازخوردها، جست و جوها و عملکرد مشتریان را به منبع بزرگی از اطلاعات ساختار نیافته تبدیل میکند که در هر لحظه تولید میشود.
پستهای شبکههای اجتماعی، پیامهای ارسال شده بین کاربران، ایمیلها و موارد بسیار دیگری روزانه اطلاعات در هم آمیختهی زیادی را تولید میکنند. مطالعات IDC نشان میدهد که اطلاعات ساختار نیافته حدود ۹۰ درصد اطلاعات دیجیتال را تشکیل میدهد. همچنین این دست از اطلاعات در دستهبندیهایی که از پیش برای رایانهها تعریف شدهاند قرار نمیگیرند.
شرایط ذکر شده چالش بزرگی و همچنین فرصت بزرگی در پیش روی تولیدکنندگان و فروشندگان قرار داده است. اگر فروشندگان بتوانند از تمام اطلاعات موجود به نتایج مورد قبولی دست یابند، فرصتهای بسیاری برای دستیابی خواهند یافت.
روش کار در پردازش زبان طبیعی
NLP آنچه که ما بیان میکنیم را تشخیص میدهد، میفهمد، خلاصه میکند و تحلیل میکند تا بتواند ما را بشناسد. نه تنها NLP به خوبی متوجه زبان ما میشود بلکه میتواند به تنهایی یک زبان ایجاد کند.
الگوریتمها، نحو و معناشناسی به دانش پردازش زبان طبیعی برای دستیابی به این توانایی کمک میکنند.
الگوریتم
الگوریتمها به NLP کمک میکنند تا زبان ارتباطی متنوع، بیساختار و پویای ما را به مفهومی تبدیل کند تا برای ماشینها قابل فهم باشد.
با استفاده از این الگوریتمها، NLP مفاهیم را از آمیخته جملات، اصطلاحات تخصصی و محاورهای زبان روزمره ما در مییابد. همچنین قادر است از آنچه که میگوییم بخشی را انتخاب کرده و آن را به یک داده تبدیل کند و صحبت ما را به شکلی تبدیل کند که کامپیوترها بتوانند آن را بفهمند.
آنالیز نحوی
نحو، دانش مربوط به چینش واژگان در جمله است. در آنالیز نحو از قوانین نحو در زبانشناسی برای درک الگوهای نحوی جملات استفاده میشود. در NLP از تکنیکهایی که بر اساس دانش بشری از نحو زبان طراحی شده، به منظور درک زبان انسانی استفاده میشود. این تکنیکها عبارتند از:
کاهش یا لمسازی (Lemmatization)
به کاهش فرمهای مختلف یک کلمه به واحدی مشخص و تبدیل واژگان به فرم لغت نامهای گفته میشود.
- تقسیمبندی واژگان (Word Segmentation)
به تبدیل متن به واحدهای کوچکتر، یعنی واژگان گفته میشود.
- تقسیمبندی مورفولوژیکی (Morphological segmentation)
در تکنیک تقسیمبندی مورفولوژیکی، واژهها را به اجزای ساختاریشان تفکیک شده که به هر یک از آنها واژک گفته میشود.
- تشخیص نقش کلمات (Part of Speech Tagging)
در این تکنیک رایانه واژگان یک متن را بر اساس اجزای کلام در آن زبان گروهبندی میکند.
آنالیز معنایی
آنالیز معنایی به بررسی ارتباط بین واژه و معنای آن و نیز به تغییر معنای واژگان در کاربردهای مختلف میپردازد. آنالیز معنایی یکی از سختترین مراحل در دانش پردازش زبان طبیعی میباشد و به کمک چندین تکنیک صورت میگیرد که در ادامه شماری از آنها را مرور میکنیم.
- شناسایی اسامی (Named Entity Recognition)
به تقسیمبندی اسامی خاص (نام افراد، اماکن، شهرها و… ) در گروههای مرتبط گفته میشود.
- ابهامزدایی از معنای کلمات (Word Sense Disambiguation)
به انتخاب بهترین معنی در بین معانی مختلف یک واژه گفته میشود.
- تولید زبان طبیعی (Natural Language Generation)
این روش مربوط به زمانی است که رایانه باید معنای جدید خلق کند و پاسخی ارائه دهد.
ابزارهای مورد استفاده در NLP
پایتون و تولکیتهای پردازش زبان طبیعی
زبان برنامهنویسی پایتون ابزارها و منابع گستردهای فراهم کرده است که برای انجام دستورهای خاص در پردازش زبان طبیعی به کار میروند.
کتابخانه (Natural Language Tool Kit) NLTK پایتون شامل منابع بسیاری میباشد که علاوه بر دستورات NLP، شامل دستورات زیرشاخههای NLP همچون تقسیم متن به واژگان، آنالیز معنایی کلماتa و غیره نیز میباشد.
NLP مبتنی بر آمار، یادگیری ماشین و یادگیری عمیق
اولین برنامههای پردازش زبان طبیعی، سیستمهای مبتنی بر قوانین بوده و بصورت دستی کدنویسی شدهاند. این برنامهها توانایی انجام دستورات مشخصی جهت پردازش زبان طبیعی را داشته اما برای استفاده در حجم وسیع مناسب نبودهاند.
NLP آماری، الگوریتم های کامپیوتری را با مدل های یارگیری ماشین و یادگیری عمیق ترکیب می کند تا به طور خودکار عناصر متن و دادههای صوتی را استخراج، طبقه بنده و برچسب گذاری کند و سپس احتمال آماری را به هر معنای ممکن آن عناصر اختصاص دهد. امروزه، مدلهای یادگیری عمیق و تکنیکهای یادگیری مبتنی بر شبکههای عصبی کانولوشن (CNN) و شبکههای عصبی مکرر (RNN) سیستمهای NLP را قادر میسازند که در حین کار، “یاد بگیرند” و معنای دقیقتری را از حجم عظیمی از متون و دادههای صوتی خام، بدون ساختار و بدون برچسب استخراج کنند.
۸ استارتاپ حوزه پردازش زبان طبیعی
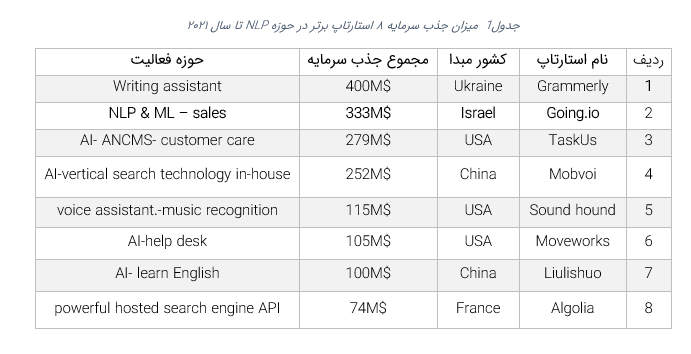
- گرامرلی یک استارتاپ اکراینی میباشد که با استفاده از پردازش زبان طبیعی یک دستیار نوشتاری فراهم کرده است. این استارتاپ از سال2009 شروع به فعالیت کردهاست. در سال ۲۰۱۹ شرکت General Catalyst با سرمایهگذاری 90 میلیون دلاری خود بر روی گرامرلی مجموع جذب سرمایه این شرکت را به ۲۰۰ میلیون دلار رسانید. General Catalyst همچنین در تنها راند قبلی جذب سرمایه گرامرلی به مبلغ 110 میلیون دلار که در سال ۲۰۱۷ اتفاق افتاد به همراه چند سرمایهگذار دیگر حضور داشته است.
ارزش استارتاپ گرامرلی از ۱ میلیارد دلار در سال ۲۰۱۹ به ۱۳ میلیارد دلار در سال ۲۰۲۱ افزایش یافته است. همچنین این شرکت با جذب سرمایه ۲۰۰ میلیون دلاری از سرمایهگذارانی چون Baillie Giffordقصد دارد سرعت رشد تیم و خلاقیت محصول را افزایش دهد.
- تسکآس یک پلتفرم آنلاین برای ارائه خدمات به شرکت های در حال رشد جهت نمایش، رشد و مراقبت از برند آنهاست. این استارتاپ آمریکایی در سال 2008 تاسیس شد و تا قبل از عرضه اولیه سهام آن در بورس توانست مجموعا 279 میلیون دلار سرمایه جذب کند. سهام تسکآس در ژانویه 2021 برای اولین بار در بازار بورس آمریکا به ارزش 23 دلار عرضه شد و هم اکنون بیش از 49 دلار ارزش دارد.
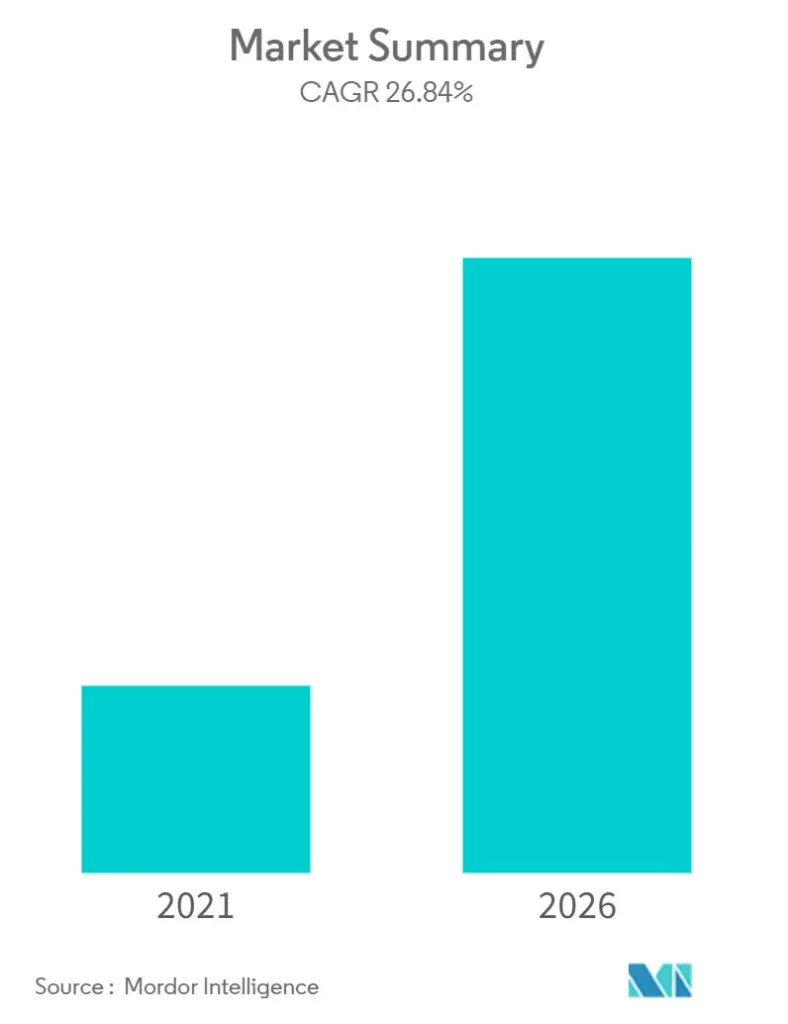
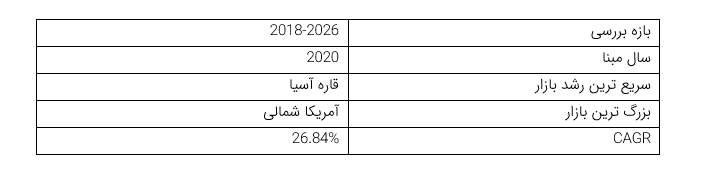
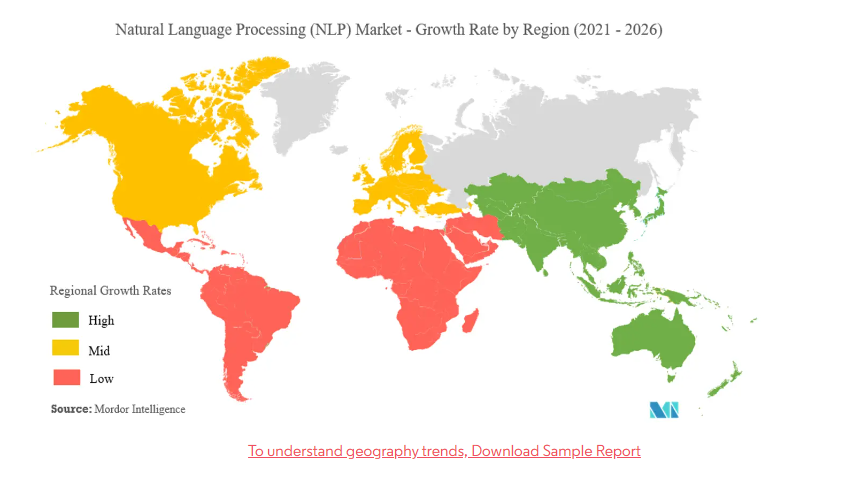
پردازش زبان طبیعی، رشد بازار، ترندها و پیش بینی ها (2021-2026)
دید کلی بازار

{kind=link}